Towards Extrinsic Dexterity Grasping in Unrestricted Environments
Abstract
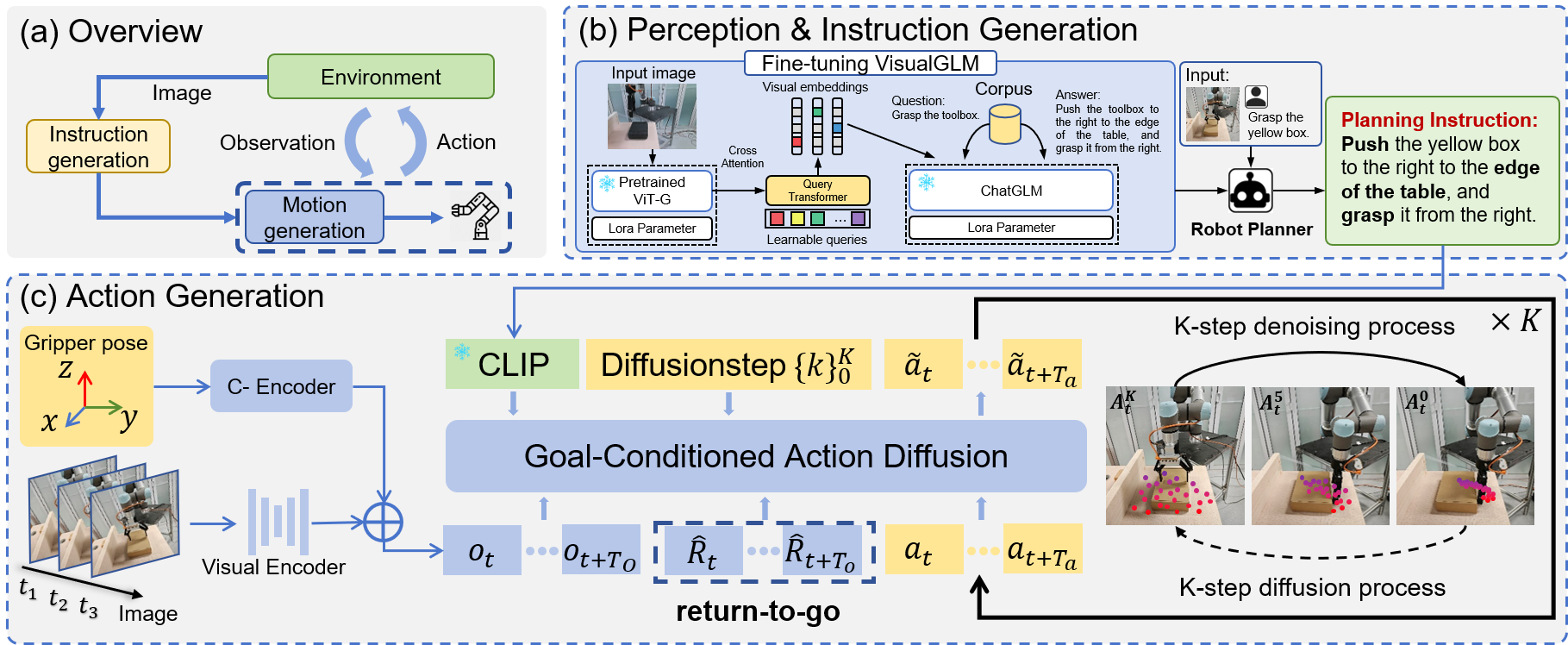
Grasping large and flat objects (e.g., a book or a pan) is often regarded as an ungraspable task, which poses significant challenges due to the unreachable grasping poses. Prior research has exploited environmental interactions through Extrinsic Dexterity, utilizing external structures such as walls or table edges to facilitate object grasping. However, they are confined to task-specific policies while neglecting semantic perception and planning to identify optimal pre-grasp configurations. This limits their operational versatility, impeding effective adaptation to varied extrinsic dexterity constraints. In this work, we present ExDiff, a robot manipulation approach for extrinsic dexterity grasping in unrestricted environments. It utilizes Vision-Language Models (VLMs) to perceive the environmental state and generate instructions, followed by a Goal-Conditioned Action Diffusion (GCAD) model to predict the sequence of low-level actions. This diffusion model learns the low-level policy, conditioned on high-level instructions and cumulative rewards, which improves the generation of robot actions. Simulation experiments and real-world deployment results demonstrate that ExDiff effectively performs ungraspable tasks and generalizes to previously unseen target objects and scenes.
Real-World Demo of Daily Life
The videos here are at 4x speed. (The grasping operation is at 1x speed)
(a) Bookshelf(seen)
(b) 3D Printer(unseen)
(c) Drawer(seen)
(d) Storage box(seen)
Real-world Demo of Push to Wall
The videos here are at 4x speed. (The grasping operation is at 1x speed)
(a) Box(seen)
(b) Toolbox(seen)
Real-world Demo of Push to Edge
The videos here are at 4x speed. (The grasping operation is at 1x speed)
(a) Box(seen)
(b) Folder(unseen)
(c) Pan(seen)
(d) Medicine cabinet(unseen)
Different Shapes of the Side of the Table
The videos here are at 4x speed. (The grasping operation is at 1x speed)
(a) Irregular edge(unseen)
(b) Curved edge(unseen)
Visualization of Rollouts on the Simulation

Depending on extrinsic dexterity structures, we get different high-level plans, and the proposed method enables precise robot manipulation on long-horizon tasks. (A) Broad, (B) Surround, (C) Basic, (D) Empty.